About
The Cornell Phonetics Lab is a group of students and faculty who are curious about speech. We study patterns in speech — in both movement and sound. We do a variety research — experiments, fieldwork, and corpus studies. We test theories and build models of the mechanisms that create patterns. Learn more about our Research. See below for information on our events and our facilities.

Upcoming Events
21st October 2022 12:20 PM
PhonDAWG - Phonetics Lab Data Analysis Working Group
Instead of discussing Grice et al. (which we will reserve for a later date), we'll continue Wednesday's PhonDAWG discussion of random vs. fixed effects.
Here are two short passages on the topic:
- Analysis of variance--why it is more important than ever, Andrew Gelman, 2005, pp. 20-21
- Growth Curve Analysis and Visualization Using R, Daniel Mirman, 2014, pp. 72-75
Location: B11, Morrill Hall
24th October 2022 01:00 PM
Dissertation defence by Maurice Jakesch: Assessing The Effects and Risks of Large Language Models in AI-Mediated Communication
Information Science PhD candidate Maurice Jakesch will defend their dissertation titled: Assessing The Effects and Risks of Large Language Model in AI-Mediated Communication. This will be a Zoom-only event.
Abstract:
Large language models like GPT-3 are increasingly becoming part of human communication. Through writing suggestions, grammatical assistance, or machine translation, the models help people to communicate more efficiently.
Yet, we have a limited understanding of how integrating them into communication will change culture and society. For example, a language model that preferably generates a particular view may change people's minds when embedded into widely used applications.
My dissertation empirically demonstrates that integrating large language models into human communication involves systemic societal risk.
In a series of experiments, I show that humans cannot detect language produced by GPT-3, that using large language models in self-presentation may damage interpersonal trust, and that interactions with opinionated language models change users' attitudes.
I introduce the concept of AI-mediated communication to explain how using large language models in communication differs from previous forms of computer-mediated communication and conclude by discussing how we can govern the risks of large language models more democratically.
Location:
26th October 2022 12:20 PM
PhonDAWG - Phonetics Lab Data Analysis Working Group
Topic is currently TBD, but most likely Sam will demo some preliminary Bayesian logistic regressions of Binna's Icelandic data.
Location: B11, Morrill Hall
26th October 2022 02:45 PM
Patrick Graybill to discuss & perform ASL Poetry
The Department of Linguistics proudly presents Patrick Graybill, Retired Faculty at the RIT National Technical Institute for the Deaf, who will lecture about & perform ASL Poetry.
On Oct. 26 from 2:45-4:00 p.m. in 110 Morrill Hall, Patrick Graybill, known as the “grandfather of ASL Poetry,” will discuss his ASL poems “Defiance,” “Liberation” and “Reflection,” during an ASL Literature class open to the public.
From 6:00-7:30 p.m. he will perform “Leaves of the Deaf Tradition” at 165 McGraw Hall. This performance will include narrations of personal experiences and folklore, some using old and now-forgotten signs, as well as several of his own poems. “All of them are, in a way, autumn leaves falling from a tree known as the Tree of the Deaf Tradition,” says Graybill.
Abstract:
Who has eighty-three years of being Deaf?
Here I am!
My name is Patrick Graybill. In my show, I will share with you what you might not know about the Deaf community in the past. I will narrate two personal stories, two folklore tales, some forgotten signs, some of my own poems based on my experiences, and a children’s story.
All of them are, in a way, autumn leaves falling from a tree known as the Tree of the Deaf Tradition.
About Patrick Graybill:
Patrick Graybill, revered as a grandfather of ASL poetry, was born in Kansas just before World War II began.
He is one of seven children; five of them, including him, were born Deaf. He has a hearing sister who is a retired sign language interpreter. In 1958, he graduated from the Kansas School for the Deaf, where an eloquent Deaf storyteller made him think seriously about becoming like her. There, he also saw his older sister in a school production of Tom Sawyer which planted in his head the desire to be an actor. He graduated from Gallaudet College with a bachelor’s degree in English in 1963 and a master’s degree in education in 1964.
He took a position as an instructor at Kendall School for the Deaf for three years. He became disillusioned with his first career and decided to study to be a Roman Catholic priest at Catholic University for two years — without interpreting services. It was a struggle that motivated him to accept an invitation to be a member of the newly established National Theatre of the Deaf. There he had a wonderful decade as a professional actor and, for a few years, operated its summer school for aspiring actors.
He retired in 2004 having been a performing arts and literature professor for 23 years at the National Technical Institute for the Deaf. He recently retired as permanent deacon for Emmanuel Church of the Deaf in Rochester, New York, after 32 years. He was conferred the degree, Doctor of Humane Letters, Honorius Causa, from St. Thomas University, Miami Gardens, Florida, in 2005.
His avocations are acting, storytelling, creating, translating texts from English into American Sign Language, and creating original poems in ASL.
Location: 110 Morrill Hall
Facilities
The Cornell Phonetics Laboratory (CPL) provides an integrated environment for the experimental study of speech and language, including its production, perception, and acquisition.
Located in Morrill Hall, the laboratory consists of six adjacent rooms and covers about 1,600 square feet. Its facilities include a variety of hardware and software for analyzing and editing speech, for running experiments, for synthesizing speech, and for developing and testing phonetic, phonological, and psycholinguistic models.
Web-Based Phonetics and Phonology Experiments with LabVanced
The Phonetics Lab licenses the LabVanced software for designing and conducting web-based experiments.
Labvanced has particular value for phonetics and phonology experiments because of its:
- *Flexible audio/video recording capabilities and online eye-tracking.
- *Presentation of any kind of stimuli, including audio and video
- *Highly accurate response time measurement
- *Researchers can interactively build experiments with LabVanced's graphical task builder, without having to write any code.
Students and Faculty are currently using LabVanced to design web experiments involving eye-tracking, audio recording, and perception studies.
Subjects are recruited via several online systems:
- * Prolific and Amazon Mechanical Turk - subjects for web-based experiments.
- * Sona Systems - Cornell subjects for for LabVanced experiments conducted in the Phonetics Lab's Sound Booth

Computing Resources
The Phonetics Lab maintains two Linux servers that are located in the Rhodes Hall server farm:
- Lingual - This Ubuntu Linux web server hosts the Phonetics Lab Drupal websites, along with a number of event and faculty/grad student HTML/CSS websites.
- Uvular - This Ubuntu Linux dual-processor, 24-core, two GPU server is the computational workhorse for the Phonetics lab, and is primarily used for deep-learning projects.
In addition to the Phonetics Lab servers, students can request access to additional computing resources of the Computational Linguistics lab:
- *Badjak - a Linux GPU-based compute server with eight NVIDIA GeForce RTX 2080Ti GPUs
- *Compute server #2 - a Linux GPU-based compute server with eight NVIDIA A5000 GPUs
- *Oelek - a Linux NFS storage server that supports Badjak.
These servers, in turn, are nodes in the G2 Computing Cluster, which currently consists of 195 servers (82 CPU-only servers and 113 GPU servers) consisting of ~7400 CPU cores and 698 GPUs.
The G2 Cluster uses the SLURM Workload Manager for submitting batch jobs that can run on any available server or GPU on any cluster node.
Articulate Instruments - Micro Speech Research Ultrasound System
We use this Articulate Instruments Micro Speech Research Ultrasound System to investigate how fine-grained variation in speech articulation connects to phonological structure.
The ultrasound system is portable and non-invasive, making it ideal for collecting articulatory data in the field.

BIOPAC MP-160 System
The Sound Booth Laboratory has a BIOPAC MP-160 system for physiological data collection. This system supports two BIOPAC Respiratory Effort Transducers and their associated interface modules.

Language Corpora
- The Cornell Linguistics Department has more than 915 language corpora from the Linguistic Data Consortium (LDC), consisting of high-quality text, audio, and video corpora in more than 60 languages. In addition, we receive three to four new language corpora per month under an LDC license maintained by the Cornell Library.
- This Linguistic Department web page lists all our holdings, as well as our licensed non-LDC corpora.
- These and other corpora are available to Cornell students, staff, faculty, post-docs, and visiting scholars for research in the broad area of "natural language processing", which of course includes all ongoing Phonetics Lab research activities.
- This Confluence wiki page - only available to Cornell faculty & students - outlines the corpora access procedures for faculty supervised research.

Speech Aerodynamics
Studies of the aerodynamics of speech production are conducted with our Glottal Enterprises oral and nasal airflow and pressure transducers.

Electroglottography
We use a Glottal Enterprises EG-2 electroglottograph for noninvasive measurement of vocal fold vibration.

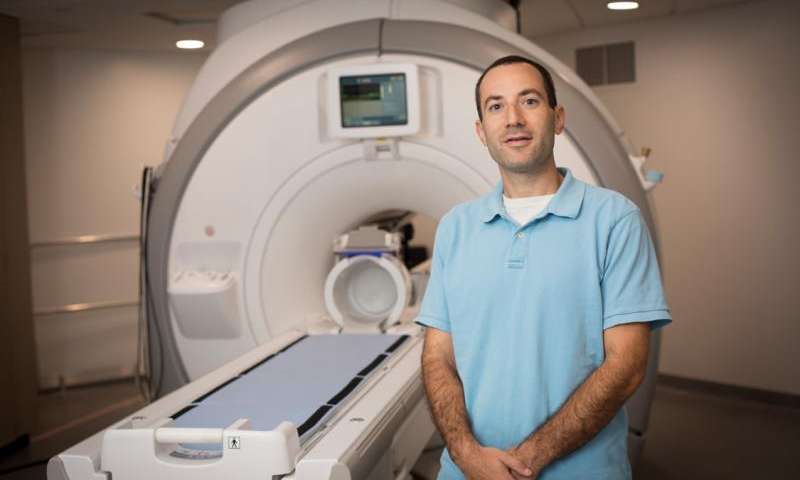
Real-time vocal tract MRI
Our lab is part of the Cornell Speech Imaging Group (SIG), a cross-disciplinary team of researchers using real-time magnetic resonance imaging to study the dynamics of speech articulation.
Articulatory movement tracking
We use the Northern Digital Inc. Wave motion-capture system to study speech articulatory patterns and motor control.

Sound Booth
Our isolated sound recording booth serves a range of purposes--from basic recording to perceptual, psycholinguistic, and ultrasonic experimentation.
We also have the necessary software and audio interfaces to perform low latency real-time auditory feedback experiments via MATLAB and Audapter.

©Copyright 2020, Cornell University