News
Seung-Eun Kim to present paper at ISSP 2020
PhD candidate Seung-Eun Kim and Dr. Sam Tilsen will present a paper titled "Evidence for F0 preplanning with delayed stimuli" at the 2020 International Seminar on Speech Production Conference.
Abstract:
Many prosodic theories hold that different syntactic structures are mapped to distinct prosodic organizations; these theories predict that acoustic and articulatory correlates of these structures differ mainly at phrase boundaries, yet no studies have investigated whether such predictions are correct.
This study uses a novel neural network-based analysis method for temporally localizing prosodic information that is associated with syntactic contrast in acoustic and articulatory signals.
Specifically, we focus on the contrast between non-restrictive and restrictive relative clauses. Neural networks were trained on multi-dimensional acoustic and articulatory data to classify the two types of relative clauses, and the network accuracies on test data were analyzed.
The results found two different patterns syntactically conditioned prosodic information was either widely distributed around the boundaries or narrowly distributed at specific locations.
The findings suggest that prosodic expression of syntactic contrasts does not occur in the uniform way or at a fixed location, but rather it is accomplished with various strategies.
3rd January 2021
Five Cornell Phonetics Lab Researchers present papers at the 12th International Seminar on Speech Production (Providence)
Five Phonetics Lab researchers presented papers at the 12th International Seminar on Speech Production (Providence), which is held Monday, Dec. 14 to Friday, Dec. 18.
- Dr. Sam Tilsen and Dr. Anne Hermes (CNRS/Sorbonne Nouvelle) - "Nonlinear effects of speech rate on articulatory timing in singletons and geminates"
- Grad Student Dan Cameron Burgdorf - "Compensation for Altered Feedback in Vowels and Glides"
- Grad Students Sireemas Maspong & Francesco Burroni - "Functional Load modulates speech production, but not speech perception: Evidence from Thai vowel length"
- Dr. Anne Hermes (CNRS/Sorbonne Nouvelle), Dr. Sam Tilsen and Dr. Rachid Ridouane (CNRS/Sorbonne Nouvelle) - "Cross-linguistic timing contrast in geminates: A rate-independent perspective"
- Grad Student Seung-Eun Kim and Dr. Sam Tilsen - "Temporal localization of syntactically conditioned prosodic information"
19th December 2020
Sireemas Maspong & Francesco Burroni present poster at ISSP 2020
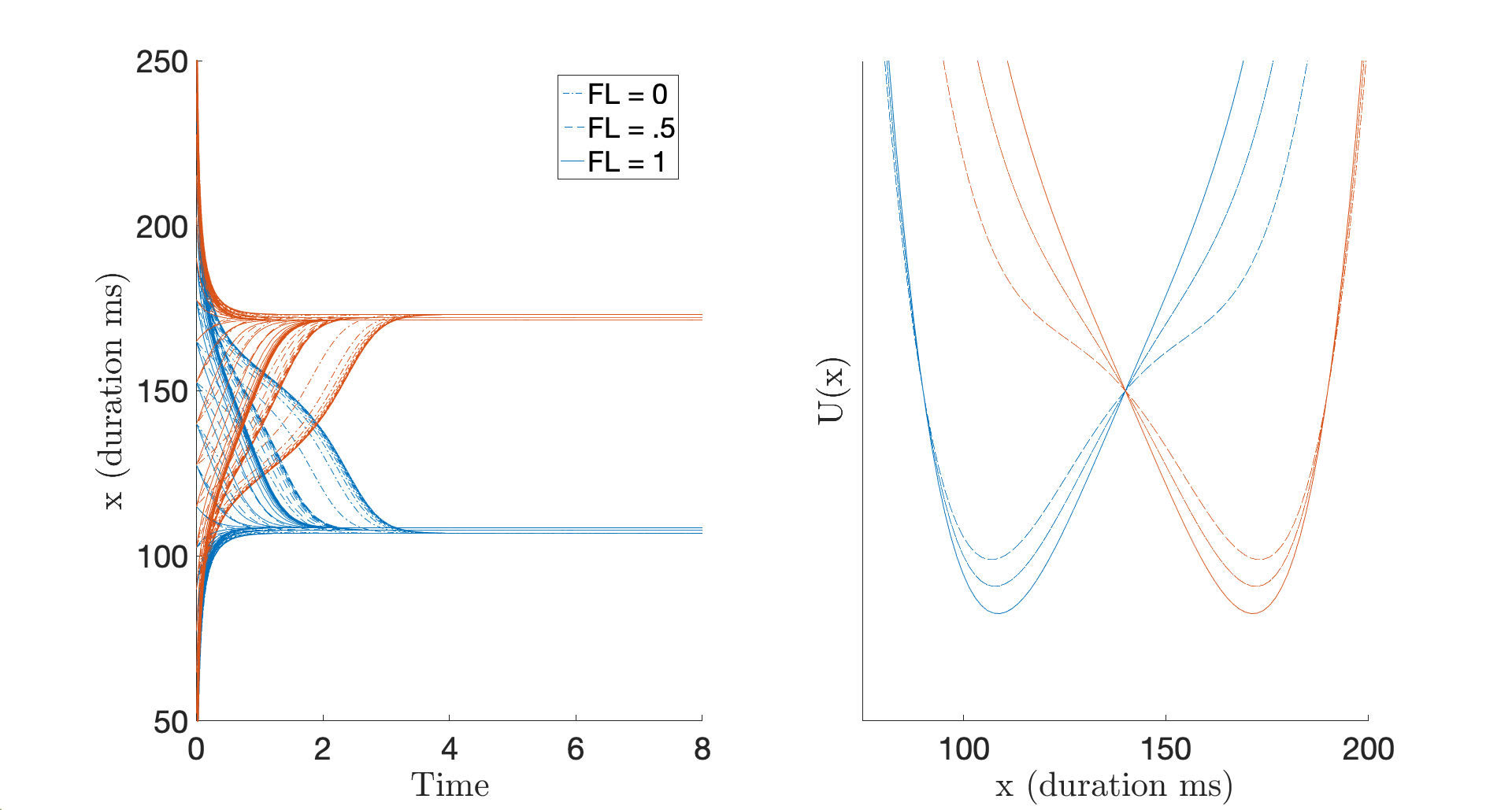
Sireemas Maspong & Francesco Burroni presented a poster titled: "Functional Load modulates speech production, but not speech perception: Evidence from Thai vowel length" at the 12th International Seminar on Speech Production (ISSP), virtually held Dec 14-18, 2020
Poster Abstract:
The functional load (FL) of a phonological contrast has been shown to correlate with its resistance to merger on evolutionary timescales. The effects of FL on day-to-day speech, however, remain an uncharted territory.
In this paper, we studied the effects of FL in a production and in a perception study of vowel length contrasts in Bangkok Thai. We found that, in production, FL had a positive correlation with long/short vowel duration ratios, as well as with the discriminability between short and long vowels distributions. In perception, we found no correlations between FL and logistic function slope of the responses or between FL and reaction times.
Elaborating on the asymmetric effects of FL on production and perception, we hypothesize that different units and mechanisms involved in each process, as well as their relationship to phonological contrast, are responsible for the asymmetry. Moreover, we discuss the implications of our findings for theories of sound change that privilege perception over production. Finally, we conclude by discussing how the real time effects of FL on vowel length contrasts production may be accommodated in a nonlinear dynamical model of phonological contrast.
18th December 2020
Seung-Eun Kim and Dr. Sam Tilsen present poster at the 12th International Seminar on Speech Production
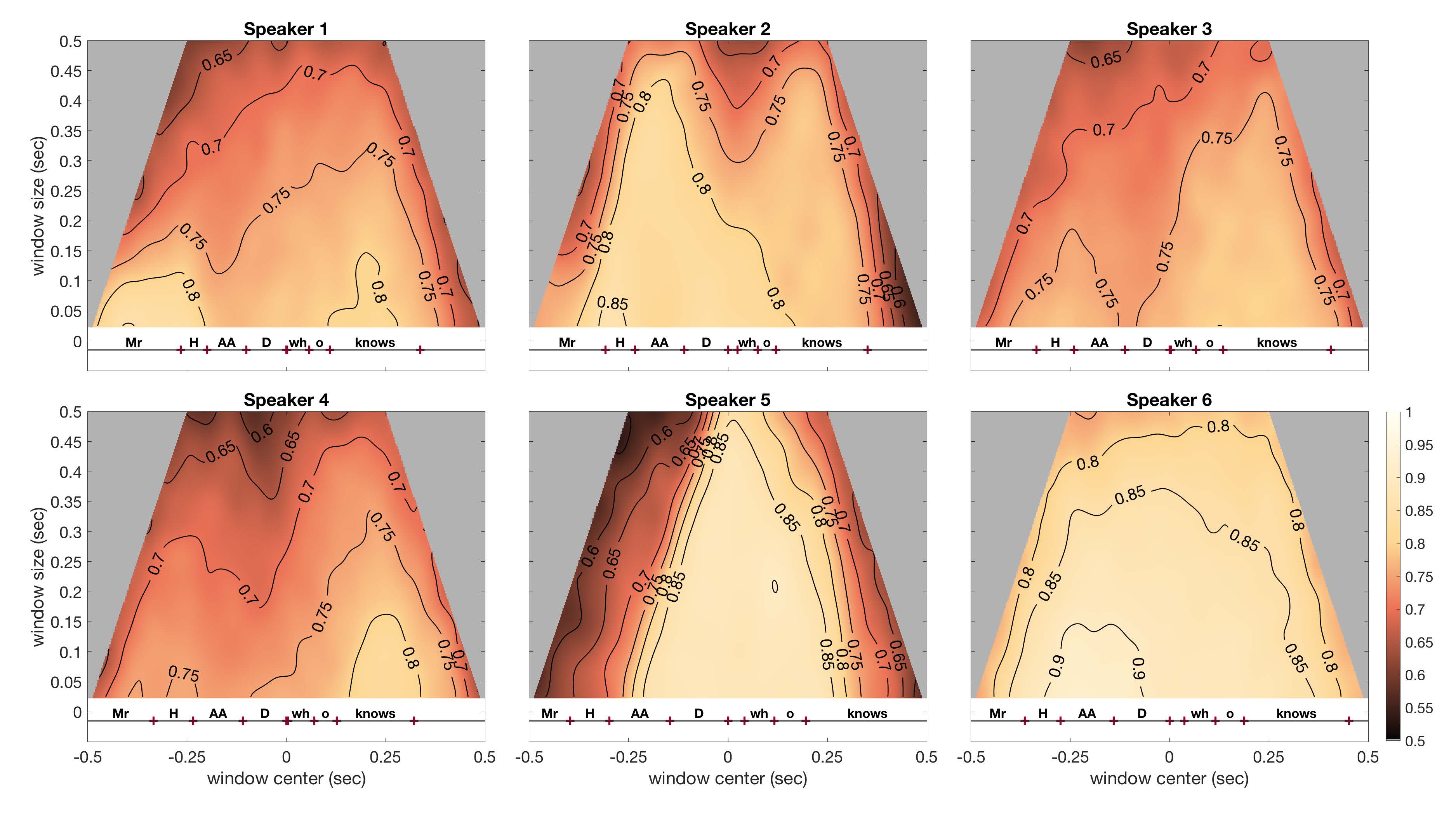
Seung-Eun Kim and Dr. Sam Tilsen present poster titled "Temporal localization of syntactically conditioned prosodic information" at the 12th International Seminar on Speech Production (ISSP 2020), held virtually on Dec 14-18, 2020.
Poster Abstract:
This study investigates when in time the prosodic correlates of a syntactic contrast can be detected in acoustic and articulatory signals.
Specifically, we attempt to localize information that distinguishes non-restrictive relative clauses (NRRCs) and restrictive relative clauses (RRCs), examples of which are shown in (1). On several accounts (e.g., Selkirk 2005), the two types of relative clauses differ in prosodic phrase structure, and this predicts that the utterances in (1) should differ in the vicinity of the phrase boundaries before (B1) and after (B2) the relative clause. To test this prediction, we used a neural network-based analysis procedure.
The results showed that for some speakers, the syntactically conditioned prosodic information was distributed in a wide region around prosodic boundaries, while for the other speakers, the information was more concentrated at specific locations. For those speakers who showed concentrated patterns, there was variation in where prosodic information was located relative to phrase boundaries.
16th December 2020
©Copyright 2020, Cornell University